Behind the Scenes of Let’s Talk: Building an AI-Powered Chat for Website Platform
Introduction: Pulling Back the Curtain on Let’s Talk
Have you ever wondered how AI-driven platforms seamlessly process user queries and deliver accurate, context-aware responses? In this deep dive, we’ll pull back the curtain on Let’s Talk, an AI-powered chat component for websites, and explore its architecture, workflows, and the tools that make it tick. Whether you’re a developer, AI enthusiast, or simply curious about modern tech stacks, this walkthrough will shed light on the magic behind the scenes.
Contents
The Two Pillars: Indexing and Query/Response Flows
Let’s Talk operates on two core workflows, visualized as blue (indexing) and green (query/response) pathways. Here’s how they work together:
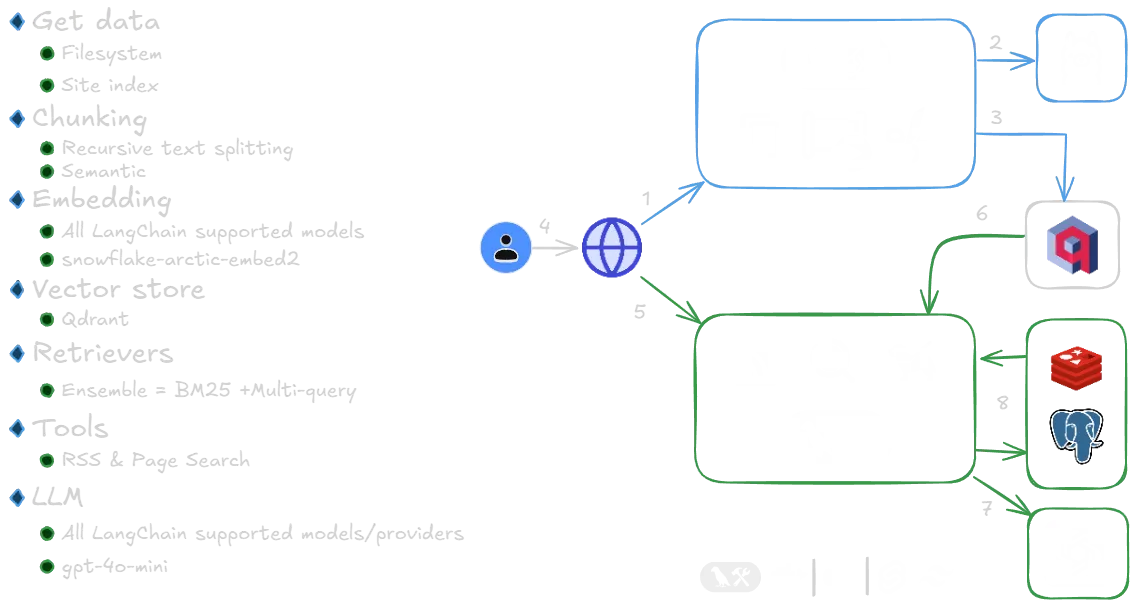
1. Indexing Flow: Organizing Knowledge
"If you can’t find it, you can’t use it."
- Input Sources:
- File System: Directly ingest structured content from local or cloud storage.
- Site Index: Crawl and index web pages or blogs for dynamic content.
- Metadata Extraction:
- Automatically pull titles, publish dates, character counts, and other metadata.
- Store metadata in CSV files for auditability and reuse.
- Chunking Strategies:
- Recursive Text Splitting: Break content into digestible chunks using configurable sizes and overlaps.
- Semantic Chunking: Group text based on contextual relevance (e.g., topics or themes).
- Embeddings & Storage:
- Embedding Model: Snowflake Arctic Embed (hosted locally via Ollama for cost efficiency).
- Vector Database: Quadrant, a performant vector store that bridges indexing and query workflows.
2. Query/Response Flow: Delivering Answers
"Ask, and the ReAct agent shall answer."
- ReAct Agent Framework:
- A reasoning engine that uses three tools:
- RSS Feed: Fetch real-time updates from subscribed sources.
- On-Site Search: Scour indexed website content.
- Hybrid Retriever: Combine BM25 (keyword-based), multi-query, and vector similarity searches for precision.
- Ensemble Weighting: Currently uses equal weights for retrieval methods but will support custom configurations.
- A reasoning engine that uses three tools:
- Response Generation:
- LLM Flexibility: Compatible with any model (e.g., GPT-4, Mistral) via LangChain APIs.
- Caching & Persistence: Built-in caching and Postgres integration for chat history and memory management.
The Tech Stack: Powering Scalability and Efficiency
Let’s Talk is built to be self-hosted, cost-effective, and modular:
- Backend: Python-driven pipelines with LangChain for orchestration.
- Observability: LangSmith for debugging and monitoring AI workflows.
- Hosting: Docker containers on private infrastructure to minimize costs.
- Frontend: A sleek Svelte web component styled with Tailwind CSS for a modern UI.
Why This Architecture Matters
- Cost Control: Local hosting of models (via Ollama) and self-managed infrastructure reduce reliance on expensive cloud services.
- Flexibility: Swap embedding models, LLMs, or vector stores without overhauling the system.
- Transparency: Metadata logging and CSV exports ensure users understand how data is processed.
What’s Next for Let’s Talk?
We’re just scratching the surface! Future updates will include:
- Customizable Retrieval Weights: Fine-tune how BM25, multi-query, and vector search contribute to results.
- Enhanced Memory: Deeper integration of conversational memory for context-aware dialogues.
- Video Demos: Step-by-step tutorials on configuring chunking strategies, debugging with LangSmith, and more.
Try It Yourself
Explore Let’s Talk in action at TheDataGuy.PRO and stay tuned for hands-on guides. Whether you’re building a FAQ bot, a research assistant, or an enterprise knowledge base, the principles here can scale to fit your needs.
Got questions or ideas? Drop a comment at YouTube—we’d love to hear how you’re leveraging AI in your projects!