
Building Your AI Data Moat: Competitive Advantage Through Proprietary Data
In my previous post "Data is King", I explored Peter Norvig's groundbreaking perspective that data, not algorithms, often drives competitive advantage in AI systems. Today, I'll expand on that foundation with practical strategies for building what venture capitalists and AI strategists now call an "AI data moat" — a defensible competitive advantage created through proprietary data assets that competitors can't easily replicate.
Why Data Moats Matter More Than Ever
The democratization of AI through open-source models and cloud APIs has dramatically lowered the barrier to implementing sophisticated AI capabilities. Today, even small startups can deploy powerful large language models with minimal technical expertise.
This democratization creates a paradox: as AI technologies become more accessible, the sustainable competitive advantage shifts decisively toward proprietary data. When everyone has access to similar algorithms, unique data becomes the primary differentiator.
Three Types of Data Moats
Not all data moats are created equal. Organizations typically develop one of three types:
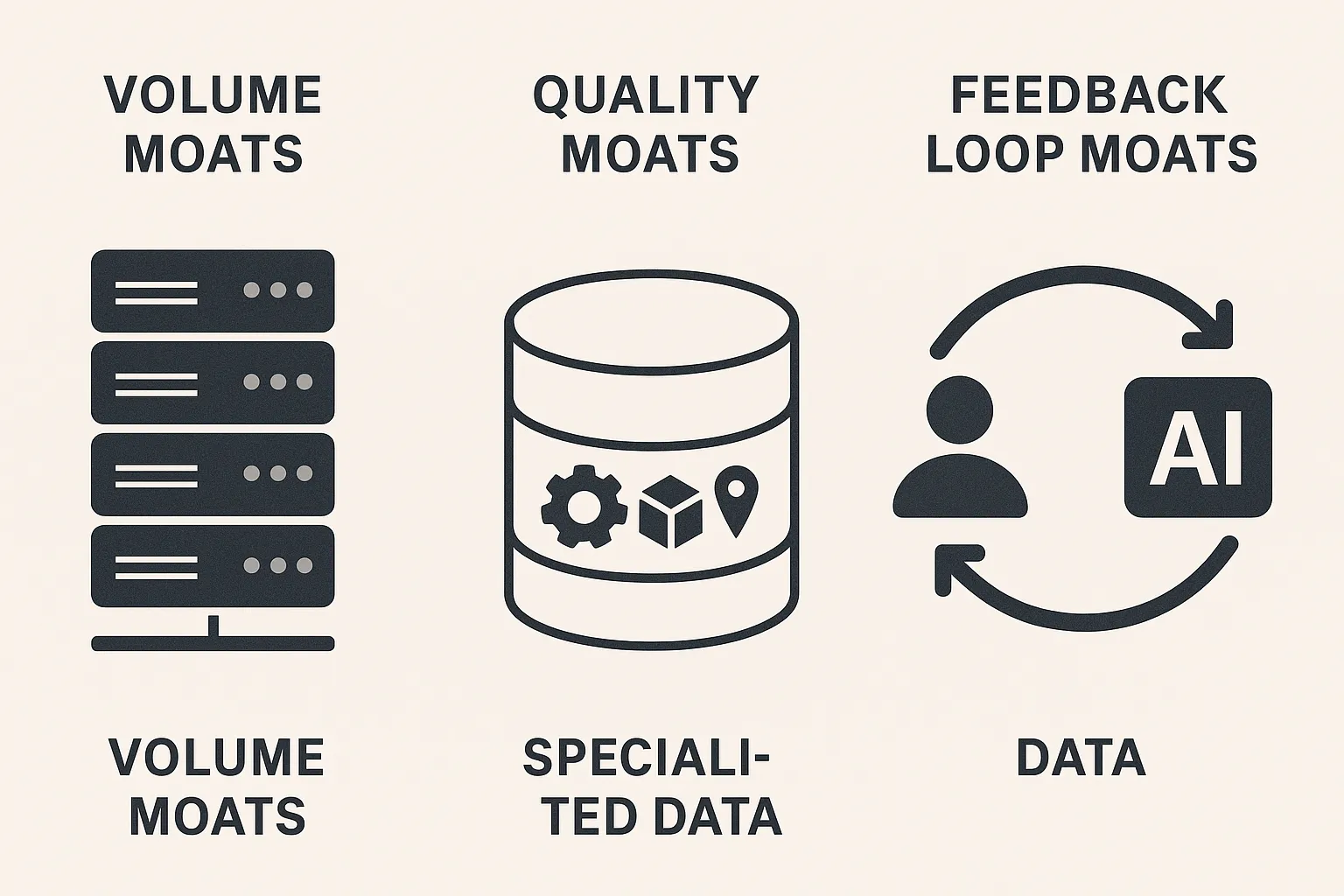
1. Volume Moats
These leverage massive quantities of data that are difficult for competitors to match. Examples include:
- Google's search data: Billions of queries providing insights into user intent
- Amazon's purchase history: Unprecedented visibility into consumer buying patterns
- Tesla's autonomous driving data: Over 5 billion miles of real-world driving scenarios
2. Quality Moats
These depend not on raw volume but on specialized, high-value data:
- Bloomberg's financial data: Meticulously curated market information
- Mayo Clinic's healthcare records: Decades of annotated patient outcomes
- IQVIA's pharmaceutical data: Comprehensive, longitudinal prescription information
3. Feedback Loop Moats
These create virtuous cycles where AI systems improve with user interaction:
- Netflix's recommendation engine: Learns from viewing patterns
- Spotify's discovery features: Refines suggestions based on listening behavior
- LinkedIn's recruiting tools: Enhance matching through hiring outcomes
Practical Strategies for Building Your Data Moat
1. Data Collection: Beyond Basic Aggregation
The foundation of any data moat is a systematic approach to collection. Here are concrete strategies:
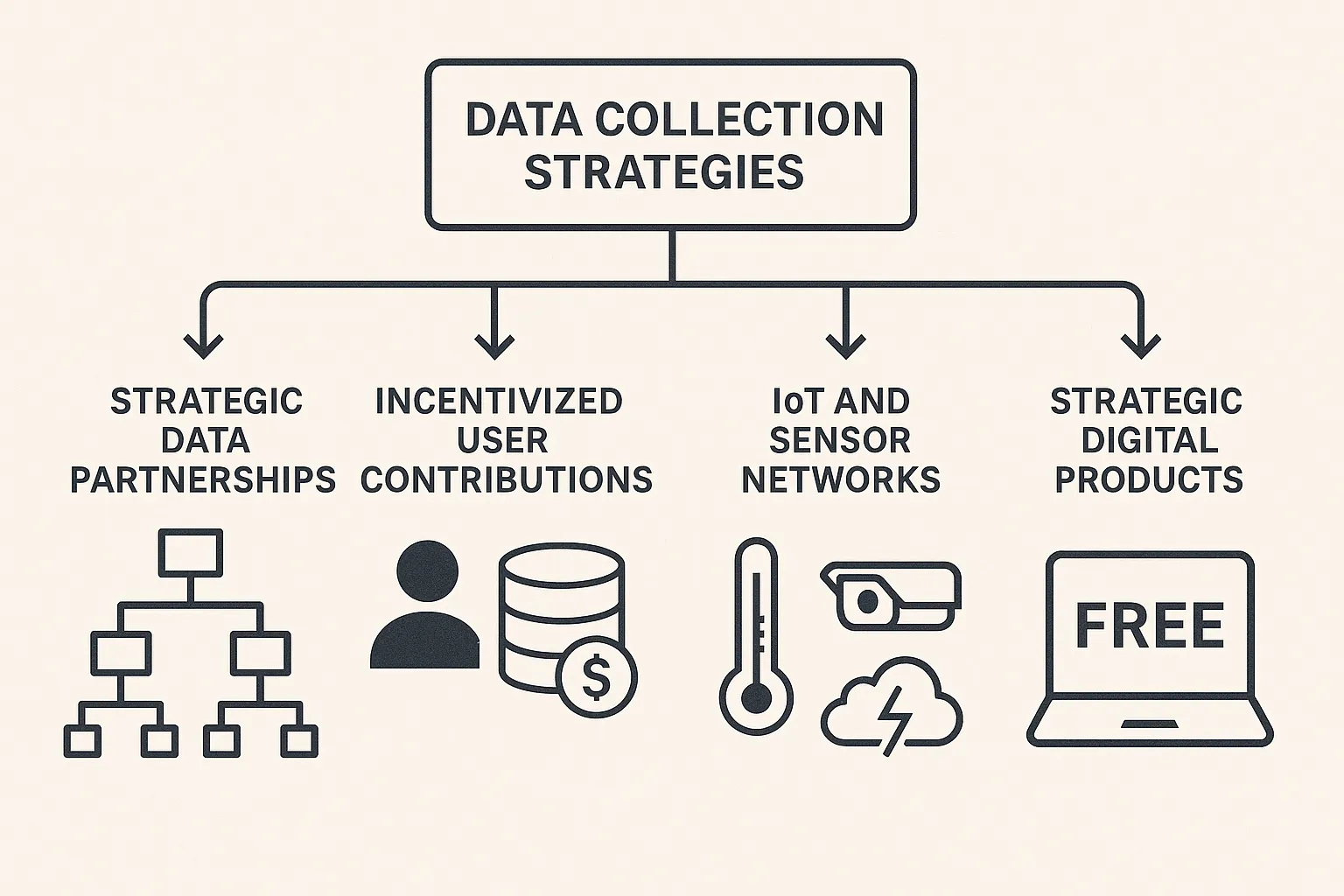
Strategic Data Partnerships
Form alliances that provide mutual data benefits:
- Retail example: A clothing retailer partners with a footwear company to create a more complete customer profile without competing directly
- Implementation tactic: Develop clear data-sharing agreements that specify ownership, usage rights, and privacy considerations
Incentivized User Contributions
Create mechanisms that reward users for providing valuable data:
- B2C example: Waze rewards users for reporting traffic conditions with gamification elements
- B2B example: Salesforce encourages customers to participate in anonymous benchmarking in exchange for industry insights
- Implementation tactic: Ensure the value exchange is transparent and proportional to the data's worth
IoT and Sensor Networks
Deploy physical sensors to capture unique real-world data:
- Agricultural example: John Deere tractors collect soil conditions across millions of farmland acres
- Implementation tactic: Focus sensors on collecting data that directly impacts your core value proposition
Strategic Digital Products
Create free or low-cost products specifically designed to gather valuable data:
- Example: HubSpot's Website Grader tool collects insights about business websites while providing value to users
- Implementation tactic: Ensure the product provides genuine utility while ethically collecting data with proper consent
2. Data Annotation: Transforming Raw Data into AI Gold
Raw data has limited value until it's structured and annotated for AI systems. Here's how to do it effectively:
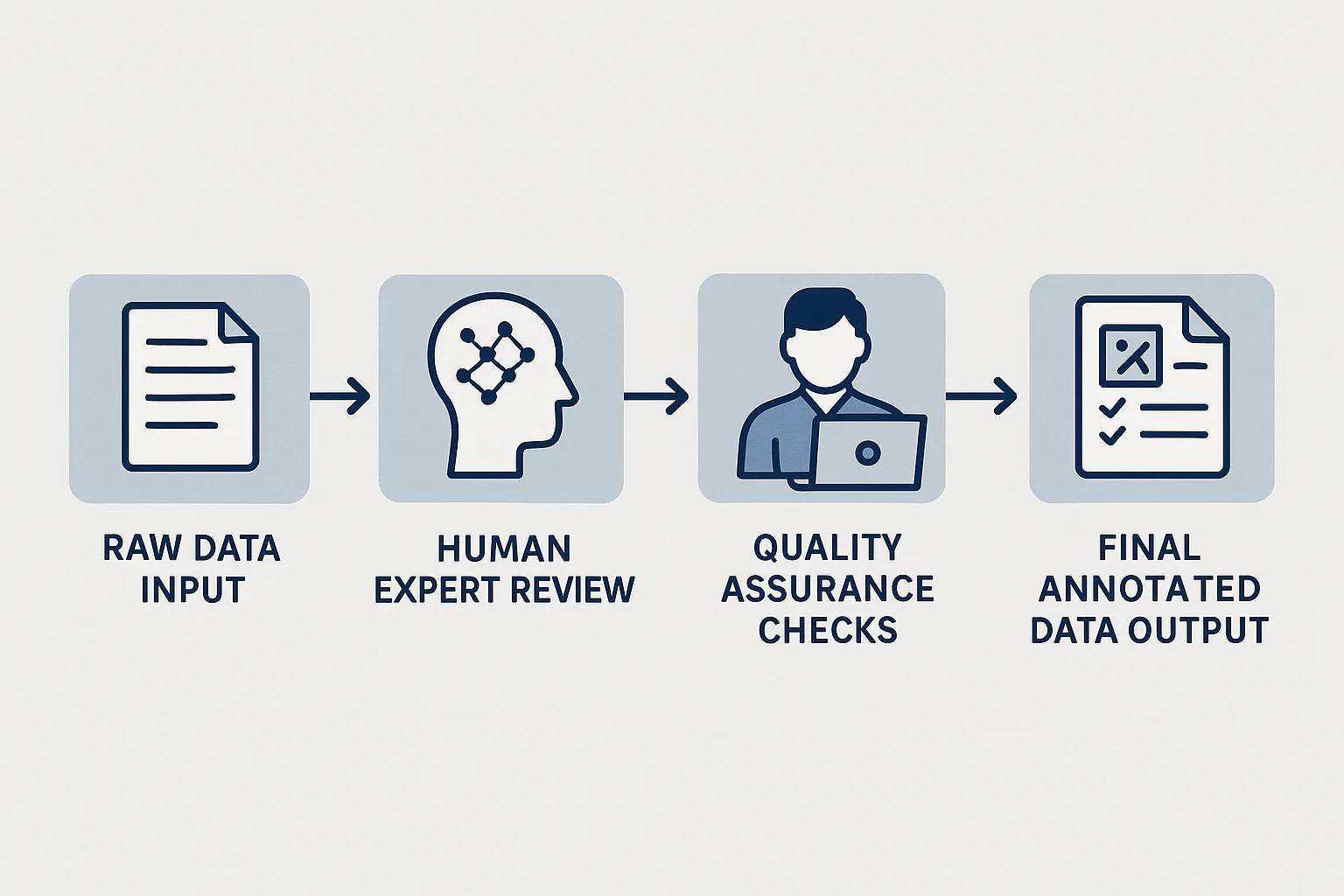
Hybrid Human-AI Annotation Pipelines
Combine human expertise with AI assistance:
- Implementation example: Use automated pre-labeling for routine cases, then have human experts review edge cases
- Cost optimization: Build workflows where AI handles 80% of annotations and humans focus on the 20% that require judgment
Domain Expert Involvement
Incorporate specialized knowledge into your annotation process:
- Healthcare example: Have radiologists annotate medical images rather than general-purpose labelers
- Legal example: Use paralegals and attorneys to label contractual documents
- Implementation tactic: Develop annotation guidelines specific to your domain with clear examples
Continuous Quality Assurance
Implement systematic quality checks throughout the annotation process:
- Implementation example: Use statistical sampling to verify a percentage of annotations
- Consensus tactics: For critical datasets, implement multi-annotator consensus protocols
- Technical approach: Calculate inter-annotator agreement scores to identify areas needing clarification
Annotation Tool Development
Create specialized tools that enhance annotation efficiency:
- Implementation example: Build semi-automated tools that learn from annotator behavior
- Cost-benefit analysis: Calculate the ROI of custom tool development versus off-the-shelf options
3. Data Protection: Securing Your Most Valuable Asset
Building a data moat is meaningless if competitors can easily access or replicate your proprietary data.
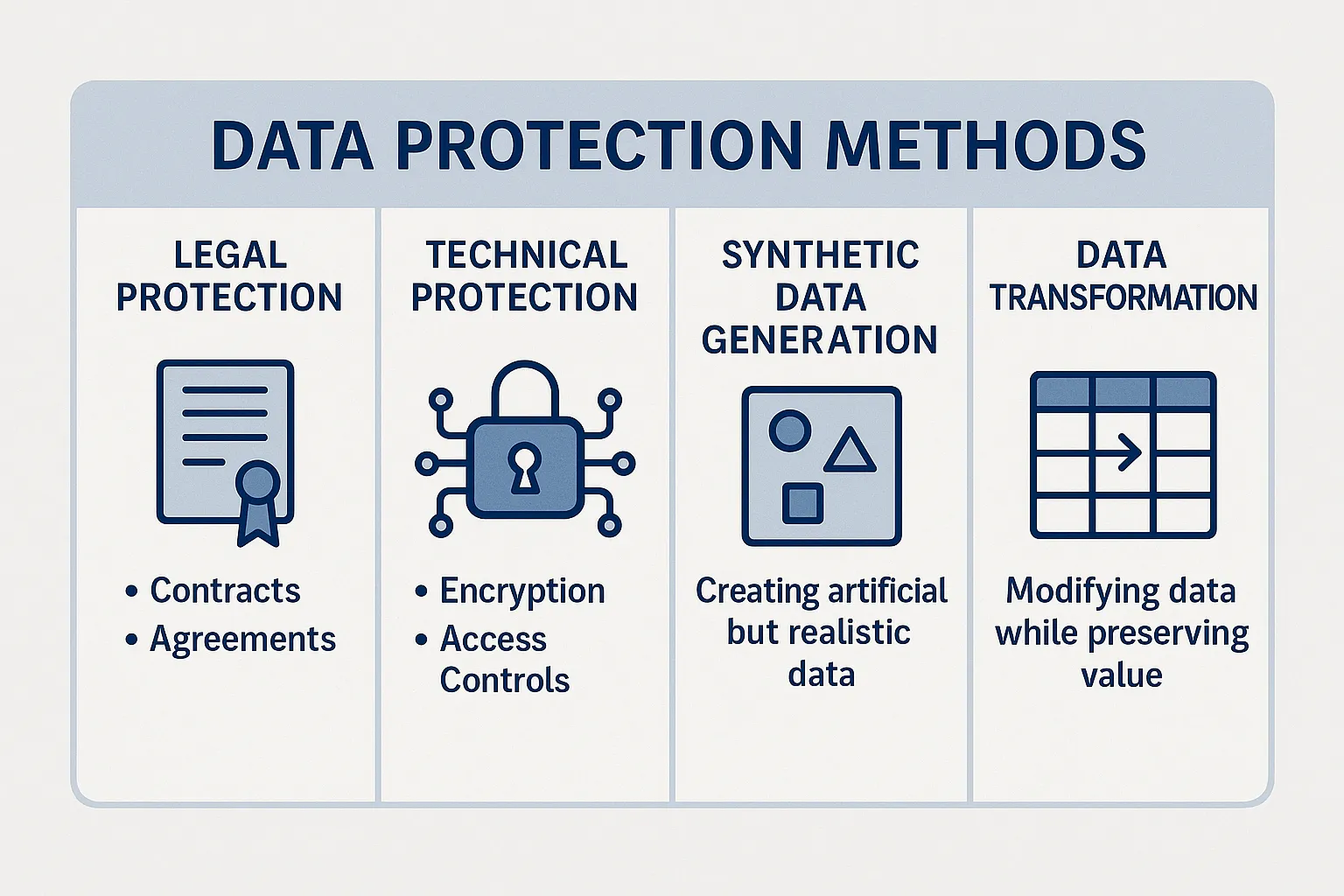
Legal Protection Strategies
Implement comprehensive legal safeguards:
- Data licensing: Create tiered data access licenses with clear usage limitations
- Employee agreements: Develop specific confidentiality provisions for data assets
- Implementation tactic: Regularly audit compliance with data handling policies
Technical Protection Methods
Deploy technologies that prevent unauthorized access or use:
- Differential privacy: Add calibrated noise to data that preserves aggregate insights while protecting individual records
- Homomorphic encryption: Allow computations on encrypted data without revealing the underlying information
- Federated learning: Train models across distributed datasets without centralizing sensitive information
- Implementation example: GitHub Copilot uses techniques to avoid reproducing substantial portions of training data verbatim
Synthetic Data Generation
Create artificial data that preserves statistical properties without exposing real data:
- Financial example: Generate synthetic transaction data for testing fraud detection systems
- Healthcare example: Create synthetic patient records for algorithm development
- Implementation tactic: Validate that synthetic data maintains the relationships and edge cases present in real data
Data Transformation and Obfuscation
Modify data to retain value while reducing replicability:
- Implementation example: Convert raw customer behavior into anonymized pattern metrics
- Practical approach: Identify the minimal data representation that preserves predictive power
Building Your Data Moat Strategy: A 5-Step Framework
Now that we've explored the components of effective data moats, here's a practical framework for developing your own:

Step 1: Data Audit and Opportunity Assessment
Begin by cataloging your existing data assets and identifying potential collections:
Key questions:
- What unique data do you already possess?
- What data could you collect that competitors can't easily access?
- Which data assets would most directly enhance your core value proposition?
Practical approach: Create a data asset inventory with assessments of uniqueness, competitive value, and current utilization
Step 2: Collection Infrastructure Development
Build systems to systematically gather and store valuable data:
Key components:
- Collection mechanisms (APIs, sensors, user interfaces)
- Storage architecture (considering scale, security, and access patterns)
- Data governance frameworks
- Privacy compliance systems
Implementation tactic: Start with minimal viable collection systems for your highest-value data, then expand
Step 3: Annotation and Enhancement Pipeline
Transform raw data into AI-ready assets:
Key elements:
- Annotation workflow design
- Quality assurance processes
- Metadata enrichment procedures
- Version control systems
Cost optimization: Calculate your annotation ROI to determine appropriate investment levels
Step 4: Protection and Compliance Framework
Secure your data moat against both legal and technical threats:
Essential components:
- Data classification system
- Access control mechanisms
- Anonymization procedures
- Legal protection strategy
Implementation approach: Conduct regular vulnerability assessments on both technical and procedural protections
Step 5: Feedback Loop Integration
Create systems that continuously strengthen your data moat:
Key mechanisms:
- User feedback collection
- Performance monitoring
- Data quality metrics
- Continuous improvement processes
Implementation example: Develop dashboards that track both data acquisition and utilization metrics
Beyond Collection: Data Synthesis as a Competitive Strategy
While collecting proprietary data remains crucial, leading organizations are increasingly creating synthetic data that combines the benefits of proprietary information without the same privacy and regulatory concerns.
Synthetic Data Advantages
- Privacy compliance: Generate realistic data without exposing sensitive information
- Edge case coverage: Create synthetic examples of rare but important scenarios
- Balanced representation: Address biases present in raw collected data
- Unlimited scale: Generate as much training data as needed
Implementation Approaches
- GAN-based generation: Use generative adversarial networks to create realistic synthetic examples
- LLM-based generation: Leverage large language models to create diverse synthetic data
- Implementation example: Fine-tune models like GPT to generate domain-specific synthetic examples
- Validation approach: Use frameworks like RAGAS (Retrieval Augmented Generation Assessment) to evaluate synthetic data quality across dimensions of faithfulness, relevance, and informativeness
- Quality control: Implement human-in-the-loop verification for critical datasets generated by LLMs
- Simulation environments: Build virtual worlds that generate data through simulated interactions
- Statistical modeling: Create synthetic data that preserves the statistical properties of real datasets
- Hybrid approaches: Combine real data with synthetic augmentation
The Ethical Dimension: Responsible Data Moat Building
Building a data moat carries ethical responsibilities that forward-thinking organizations must address:
Ethical Considerations
- Transparency: Be clear with users about data collection and usage
- Consent: Obtain meaningful permission for data collection
- Fair value exchange: Ensure users receive appropriate benefits for their data
- Algorithmic fairness: Prevent moats from reinforcing biases or disadvantaging certain groups
Implementation Framework
- Ethics review boards: Establish oversight for data collection and usage
- Regular impact assessments: Evaluate how your data moat affects various stakeholders
- Community engagement: Involve representatives from affected communities
- Clear documentation: Maintain transparent records of data sources and applications
Conclusion: Your Data Moat as Strategic Imperative
As AI capabilities become increasingly commoditized, proprietary data emerges as the critical differentiator for sustainable competitive advantage. Organizations that systematically collect, annotate, and protect unique data assets will establish defensible positions in the AI economy.
Remember that building an effective data moat requires:
- Strategic vision about which data truly matters
- Systematic processes for collection and enhancement
- Technical and legal protection mechanisms
- Ethical frameworks that maintain user trust
Most importantly, a data moat isn't built overnight. The most valuable data assets often accumulate through consistent, deliberate efforts over time. The best time to start building your data moat was years ago. The second-best time is today.
How "TheDataGuy" Can Help
As an experienced data strategist, I help organizations:
- Identify their most valuable potential data assets
- Design efficient collection and annotation systems
- Develop protection strategies for proprietary data
- Create feedback loops that continuously strengthen data moats
If you're ready to transform your data from a byproduct into a strategic asset, let's talk about building your organization's AI data moat.
Let's Connect
Connect with me on LinkedIn to discuss how I can help your organization build an effective AI data moat strategy.